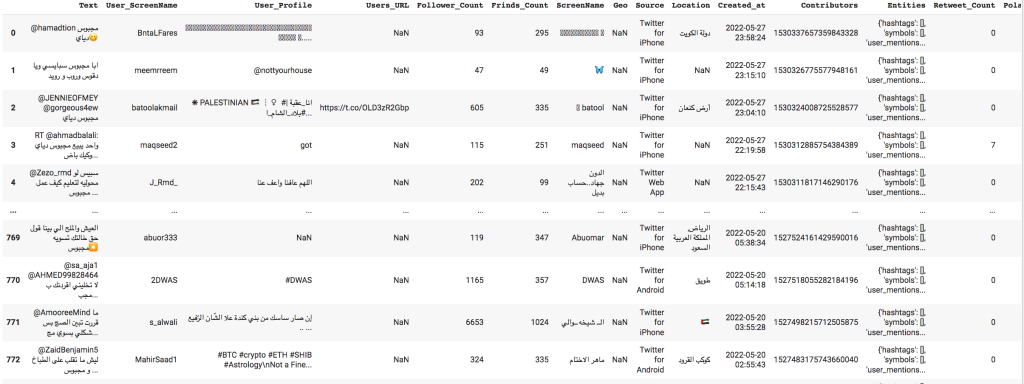
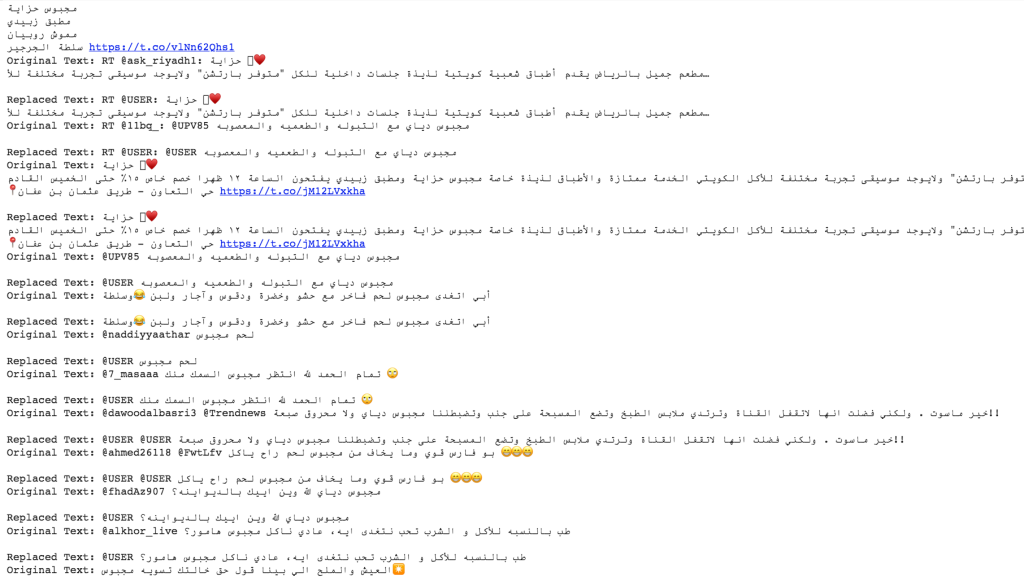
# This function removes all punctuations from the tokens
def removingPunctuation(text):
arabicPunctuations = [".","`","؛","<",">","(",")","*","&","^","%","]","[",",","ـ","،","/",":","؟",".","'","{","}","~","|","!","”","…","“","–"] # defining customized punctuation marks
englishPunctuations = string.punctuation # importing English punctuation marks
englishPunctuations = [word.strip() for word in englishPunctuations] # converting the English punctuation from a string to array for processing
punctuationsList = arabicPunctuations + englishPunctuations # creating a list of all punctuation marks
cleanTweet = ''
for i in text:
if i not in arabicPunctuations:
cleanTweet = cleanTweet + '' + i
return cleanTweet
tokenFiltered = []
for i in tokens:
token = removingPunctuation(i)
tokenFiltered.append(token)